1. 简介
在开发JavaEE应用时,使用代码读写数据库是最常使用的操作之一,所以提高这持久层的效率对提高整个项目的效率很有帮助,同时,很多的性能瓶颈也可能存在于这一层,所以很有必要掌握好这层中涉及到的一些技术。今天希望通过总结在项目中遇到的一些问题,来分享JavaEE项目中经常使用到的持久层的一些技术点。
2. 持久层的两大技术流派
在JavaEE的发展过程中,持久层的技术主要形成了两种流派,一种是基于对象映射的方案(ORMapping),另一种是基于统一管理SQL的方案。
对象映射流派。 基于对象映射的流派是将面向对象的思想延续到持久层,这个流派认为所有的表及表之间的关系都可以转换为Java对象及Java对象间的关系,他提供了一套配置Java对象与数据库对象间映射的规则和配套工具。这个流派在行业中受到广泛支持,以至于sun制定了JPA规范(Java Persistence API),所以这个流派的应用非常广泛,他的代表性框架为Hibernate,在平时的项目上,我们经常使用JPA配合Hibernate的实现来完成持久层的工作,在Java实体上写注解,使用JPA的API完成增删改查操作,非常方便快捷,在后面的章节会将相关的技术点进行介绍。
SQl统一管理流派。 SQL统一管理流派的出现较对象映射流派早,他是一种“半自动化”的持久层框架,他将写SQL的权利充分的释放给程序员,在对性能要求极高的场景下是一个非常不错的选择。这个流派的代表框架为mybatis,目前在开发的项目中还没有使用过,后续使用了再来补充详细的内容。
3. 对象映射流派(ORMapping)
在真实的项目开发中,我们经常使用的组合是:使用JPA的API来完成增删改查,使用Hibernate作为JPA规范的实现框架,使用注解完成实体对象与数据库对象的映射配置。在这个组合的使用过程中,实体间关系映射的配置需要一些经验,下面将经常遇到的疑惑和容易犯的错误进行简单总结,希望对大家有帮助。
3.1 实体间映射关系配置
3.1.1 映射关系的作用
给实体间设置映射关系后,就可以通过JPA或ORMapping框架的API,轻松的获得实体中复杂的属性(如:对象、对象集合),而不用自己写冗余重复的sql,同时框架还提供自动建表等功能。这样能减少差错率,提高开发效率,当然这只是ORMapping框架的好处之一,其他好处不再赘述。
3.1.2 实体间映射关系介绍
总的来说实体间映射关系有:继承、一对一、一对多和多对多几种关系,细分起来他们又有单向和双向之分:
约束:To前面的代表本实体,To后面的代表另一实体
- OneToOne:本实体中只有单个的另一个实体,另一实体中也只有单个的本实体
- OneToMany:本实体中有多个的另一个实体,另一实体中只有单个的本实体
- ManyToOne: 本实体中只有单个的另一个实体,另一实体中只有多个的本实体
-
ManyToMany: 本实体中只有多个的另一个实体,另一实体中只有多个的本实体
- 单向:表示可以从本实体获得另一实体,而另一实体却不能反向获得本实体
- 双向:表示关联的双方可以互相获得
3.1.3 如何配置映射
小结:
1.单向时,另一实体中不要声明本实体,且反端不配置注解 注意:用单向OneToMany时,ORMapping框架默认会使用中间表的方式来实现,但大多情况下,都希望使用外键实现,这时我们可以通过添加@JoinColumn注解来实现,例如:
//以Group - User 为例说明
Group{
@OneToMany
@JoinColum(name="group_id")//user中生成的数据库字段名
public Set getUser(){
}
}
</pre>
2.双向一对一时,根据业务判断出,被主要操作的一端(有时候两端差不多,那就随便加),在这端加上`mappedBy`和`cascade = { CascadeType.ALL }, fetch = FetchType.LAZY`,其中cascade和fetch的值,根据实际情况来确定[可参考](http://www.blogjava.net/stone840/archive/2013/03/05/396062.html)。
3.双向一对多关系时,集合上要写`mappedBy`和`cascade = { CascadeType.ALL }, fetch = FetchType.LAZY`,其中cascade和fetch的值,根据实际情况来确定[可参考](http://www.blogjava.net/stone840/archive/2013/03/05/396062.html),例如:
@Entity
public class Person implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
private String name;
private int age;
@OneToMany(cascade = { CascadeType.ALL }, fetch = FetchType.LAZY, mappedBy = "person1")
private List cellPhones;
// Getters and Setters
}
@Entity
public class CellPhone implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
private String manufacture;
private String color;
private Long phoneNo;
@ManyToOne
private Person person1;
// Getters and Setters
}
</pre>
4.双向多对多时,根据业务判断出,被主要操作的一端(有时候两端差不多,那就随便加),在这端加上`mappedBy cascade = { CascadeType.ALL }, fetch = FetchType.LAZY`,其中cascade和fetch的值,根据实际情况来确定[可参考](http://www.blogjava.net/stone840/archive/2013/03/05/396062.html)。
#### 3.1.4 如何确定实体间的映射关系
根据业务的实际需要确定,简单来说,就是按两实体在各自实体中的声明来确定,具体方法间例子;千万不要根据业务对象之间的关系来确定,因为大部分时候,业务对象间的关系可以很灵活,多对一可以,多对多也对,只有业务需要才是根本。
例子:
你想在A实体里获得B实体,即在A实体中定义了一个B实体,那么就确定好了B实体在A实体中的注解为`@XToOne`,X需要通过A实体在B实体的定义来确定,如果在B实体有一个A实体的集合属性,那么这个X就是Many,即B实体在A实体中的注解为`@ManyToOne`,A实体在B实体中的注解为`@OneToMany`,如果在B实体有一个A实体属性,那么这个X就是One,即B实体在A实体中的注解为`@OneToOne`,A实体在B实体中的注解为`@OneToOne`,如果在B实体没有A实体属性,那么这个X就既可以是One也可以是Many,即B实体在A实体中的注解为`@OneToOne`或`@ManyToOne`。
例子有点绕,多推敲几遍就会领会了。
### 3.2 一些注意点
#### 3.2.1 CascadeType
在配置`@OneToMany`的过程中一定会用到`cascade`选项,那`cascade`到底能配置哪些值,分别发挥什么作用呢?API中给出的内容不太容易理解,下面结合实践中的感悟,给出自己的理解(在单向关联的场景下):
- CascadeType.PERSIST:当**保存**一个复杂对象时,如果其中有一个对象未被持久化(也就是没有入库),那么如果配置了此项,Hibernate会先保存那个小对象,然后再保存那个复杂对象自己,如果未配置此项,会抛出异常。
- CascadeType.MERGE:当**更新**一个复杂对象时,如果其中有一个对象未被持久化(也就是没有入库),那么如果配置了此项,Hibernate会先更新那个小对象,然后再更新那个复杂对象自己,如果未配置此项,会抛出异常。
- CascadeType.REMOVE:当**删除**一个复杂对象时,如果配置了此项,Hibernate会删除数据库中相关联的子对象记录,如果未配置此项,则只会更新子对象的表,将子对象的关联字段置为`null`,而不删除子对象记录。
- CascadeType.REFRESH:没有实战过,从文档中看,大概是为了处理脏读而设置的选项。
- CascadeType.ALL:包括以上4项的所有功能。
#### 3.2.2 FetchType
在配置`@OneToMany`的过程中一定会用到`fetch`选项,那`fetch`到底能配置哪些值,分别发挥什么作用呢?
- FetchType.LAZY:只查出主对象,子对象在使用到的时候再查,使用这个选项会出现典型的`1+n`现象,即1条sql查出一个结果集,n条sql查出每个结果集中记录的详细。
- FetchType.EAGER:通过`join`的方式查出主对象及其关联的子对象,只发一条sql。
在项目中如何取舍呢?
- 大部分的场景下使用`FtetchType.LAZY`策略是能被接受的,因为项目中的绝大部分场景都只是要使用对象的一些"浅层"属性(例如:列表展现),所以使用`FtetchType.LAZY`能提高查询的效率,而且,项目中大部分的查询都带分页,结果集的条数不会很多,即使出现`1+n`的现象,在查询条数不多的情况下,效率也是很高的。
- 如果能明确的知道每次使用某个实体时都要使用到他的某个子对象,这种情况下就要使用`FetchType.EAGER`策略了。
- 当出现`FtetchType.LAZY`与`FetchType.EAGER`使用出现冲突时,可以考虑通过写`HQL`结合`join`语法的方式来变相的实现`FetchType.EAGER`的效果。
#### 3.2.3 事务
在现代项目中,一般都使用`Spring`提供的声明式事务来实现项目中事务的管理。即在需要事务的类或方法上写`@Transactional`注解,这样便能给这个类或方法添加上事务。但在开发过程中,可能会遇到因为代码的嵌套层级多或调用关系复杂后,带来`嵌套事务`问题,即一个有事务的方法调用了另一个类的拥有事务的方法,在这种情况下,事务会按照最小的颗粒执行,即如果被调用的方法中出现了事务问题,被调用的方法中会保持事务的原子性,但调用他的方法中的事务将达不到原来的目的。`嵌套事务`在实际开发中一定要有意识的避免,要搞清楚嵌套方法间的层级关系及其是否拥有事务能力。
#### 3.2.4 Hibernate操作对象的三种状态
- 持久状态(Persistent):被Hibernate操作过的对象,这个操作包括查询、保存、更新。
- 瞬时状态(Transient):new出来的对象或从前台传回来的对象,总之不是经过Hibernate操作过(persist、find、merge)的对象。
- 脱管状态(Detached):本来使持久状态的,执行了evict()或session关闭后的对象。
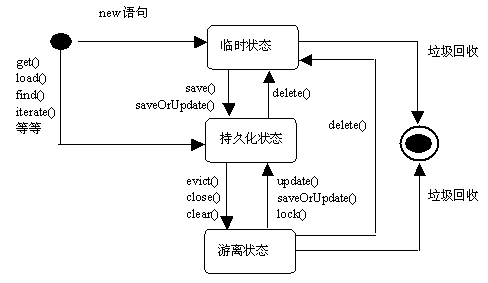
**要注意的一点是:在具有事务的情况下,如果对持久状态的对象进行了操作,Hibernate会自动将持久状态对象变动的内容持久化到数据库中。**
#### 3.2.5 更新操作
在面向对象的框架中,**更新动作的实质转变成了对象的合并操作**。将new出的对象或前台传回的对象中的内容合并到从原数据库中的对象上,再将这个合并完成的对象进行持久化就完成了更新操作。
## 4. SQL统一管理流派
目前在开发的项目中还没有使用过,后续使用了再来补充详细的内容。